H3: The Artometrics of A YouTube Dynasty


H3 is not one channel — it is a network. Since 2011, Ethan and Hila Klein have built four YouTube channels, one clothing brand, a podcast empire, and one of the most documented creator controversies in platform history. This report analyzes 1,638 videos, 680 podcast episodes, and three years of Reddit data to map the full arc: the Frenemies mountain, the duration drift nobody noticed, and the moment Klein used copyright law to shut down his own critic community.
The data is original, built from scratch via the YouTube Data API v3 and the Arctic Shift Reddit Archive. Full dataset at github.com/Artometrics/h3.
The H3 ecosystem is not a single channel — it is a network. h3h3Productions launched in 2011 as a reaction-and-commentary channel built around a Fair Use legal fight that briefly made Ethan Klein a cause célèbre in YouTube creator circles. The H3 Podcast launched in 2017 as a separate channel and quickly became the brand's primary vehicle. Hila Klein's channel documents the Teddy Fresh clothing brand. The Ethan Klein channel captures solo content and live streams. This report analyzes all four: 1,638 videos after filtering Shorts and zero-view uploads from the original 1,876-video pull via the YouTube Data API v3.
H3's trajectory cannot be understood without the era framework. The podcast's baseline (2017–2020) established the format: long-form conversation between Ethan and Hila, irregular cadence, modest but loyal viewership. The Frenemies Era (September 2020 – June 2021) is the single most-watched stretch in H3 Podcast history — nine months in which Ethan co-hosted with Trisha Paytas, generating a level of weekly engagement the show has never approached since. The Leftovers Era (September 2021 – October 2023) brought a political co-host in Hasan Piker, a different kind of audience, and a deeper ideological identity for the brand. When Leftovers ended over disagreements about the Israel-Palestine conflict, H3 entered its current post-format phase: fewer episodes, longer runtimes, a shrinking but committed core audience.
The core dataset was built from scratch using the YouTube Data API v3, stored at github.com/Artometrics/h3. Podcast episode metadata comes from the Podchaser API (680 episodes, April 2026 pull). Reddit post data was pulled from the Arctic Shift Reddit archive, covering r/h3h3productions (749,974 posts, 2014–2026) and r/h3snark (25,766 posts, April 2023–2026) — the fan sub and the critic sub, both active during the most contentious period in the brand's history.
H3 is one of the most data-rich creator brands on the internet. The combination of YouTube longevity (13 years), a documented era structure, an unusually organized fan and critic community, and a clothing brand with its own Wikipedia page creates a dataset that rewards analysis. This report does not take a position on the controversies. It reads the numbers and describes what they show.
-- H3 Master Dataset: Filter and Era Classification
-- Source: YouTube Data API v3 via Artometrics Original Pull
SELECT
channel,
title,
date,
view_count,
duration_minutes,
DATE_TRUNC('month', date) AS month_floor,
CASE
WHEN date < '2020-09-15' THEN 'Podcast Launch'
WHEN date BETWEEN '2020-09-15' AND '2021-06-08' THEN 'Frenemies Era'
WHEN date BETWEEN '2021-09-26' AND '2023-10-07' THEN 'Leftovers Era'
ELSE 'Post-Leftovers'
END AS era
FROM h3_master
WHERE duration_minutes > 1
AND view_count > 0
ORDER BY date ASC;
-- Reddit Indexing Query (mirrors Chart 3 construction)
WITH monthly_counts AS (
SELECT
source,
DATE_TRUNC('month', date) AS month,
COUNT(*) AS n_posts
FROM (
SELECT 'r/h3h3productions' AS source, date FROM h3_reddit_posts
UNION ALL
SELECT 'r/h3snark' AS source, date FROM h3_snark_posts
) combined
GROUP BY source, DATE_TRUNC('month', date)
),
subreddit_averages AS (
SELECT source, AVG(n_posts) AS avg_posts
FROM monthly_counts
GROUP BY source
)
SELECT
mc.source,
mc.month,
mc.n_posts,
ROUND((mc.n_posts / sa.avg_posts) * 100, 1) AS index
FROM monthly_counts mc
JOIN subreddit_averages sa ON mc.source = sa.source
WHERE mc.month >= '2023-04-01'
ORDER BY mc.source, mc.month;
import pandas as pd
import numpy as np
# ── 1. Load Master Dataset ───────────────────────────────────
df = pd.read_csv("data/h3_master.csv", parse_dates=["date"])
df_clean = df[(df["duration_minutes"] > 1) & (df["view_count"] > 0)].copy()
print(f"Raw videos: {len(df):,}")
print(f"After filter: {len(df_clean):,}")
print(f"Dropped: {len(df) - len(df_clean):,}")
# Raw: 1,876 | After filter: 1,638 | Dropped: 238
# ── 2. Channel Coverage ──────────────────────────────────────
channel_summary = (
df_clean
.groupby("channel")
.agg(
videos = ("view_count", "count"),
total_views = ("view_count", "sum"),
median_views = ("view_count", "median"),
first_video = ("date", "min"),
last_video = ("date", "max")
)
.sort_values("total_views", ascending=False)
)
print(channel_summary.to_string())
# ── 3. Era Flag ──────────────────────────────────────────────
def assign_era(date):
if date < pd.Timestamp("2020-09-15"): return "Podcast Launch"
elif date < pd.Timestamp("2021-06-08"): return "Frenemies Era"
elif date < pd.Timestamp("2023-10-07"): return "Leftovers Era"
else: return "Post-Leftovers"
df_clean["era"] = df_clean["date"].apply(assign_era)
era_views = (
df_clean[df_clean["channel"] == "H3 Podcast"]
.groupby("era")["view_count"]
.agg(["sum", "median", "count"])
)
print(era_views)
# ── 4. Podchaser Diagnostics ─────────────────────────────────
eps = pd.read_csv("data/h3_podchaser_episodes.csv", parse_dates=["airDate"])
print(f"Episodes: {len(eps):,}")
print(f"Date range: {eps['airDate'].min().date()} to {eps['airDate'].max().date()}")
print(f"Median runtime: {eps['length_min'].median():.0f} min")
print(f"Max runtime: {eps['length_min'].max():.0f} min")
# ── 5. Reddit Coverage Check ─────────────────────────────────
fans = pd.read_csv("data/h3_reddit_posts.csv", parse_dates=["date"])
snark = pd.read_csv("data/h3_snark_posts.csv", parse_dates=["date"])
print(f"r/h3h3productions: {len(fans):,} posts | "
f"{fans['date'].min().date()} to {fans['date'].max().date()}")
print(f"r/h3snark: {len(snark):,} posts | "
f"{snark['date'].min().date()} to {snark['date'].max().date()}")
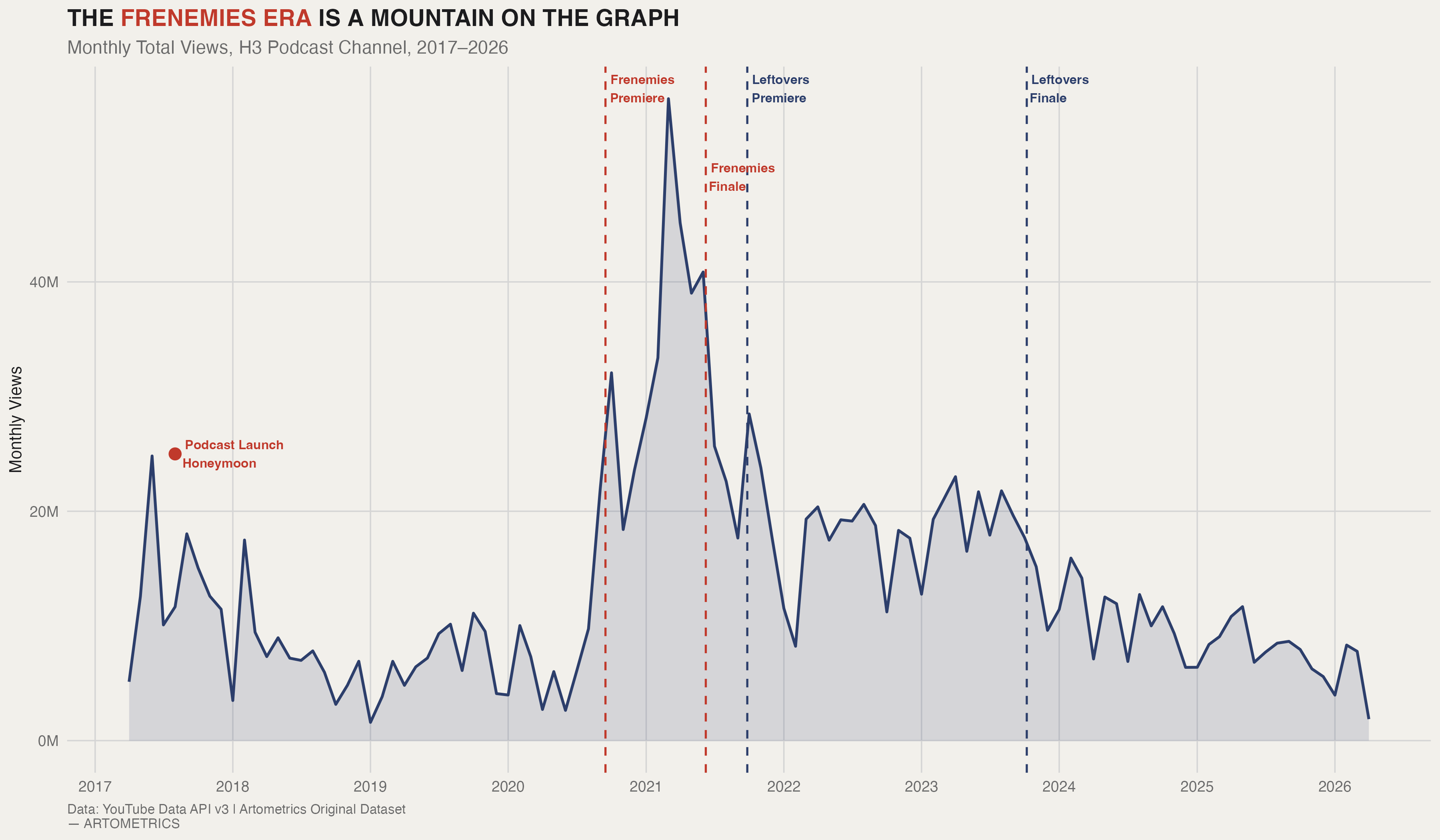
The shape of this chart tells you almost everything you need to know about the H3 Podcast's commercial arc. From 2017 to mid-2020, the show built a reliable if unspectacular baseline — a few million views per month, loyal audience, consistent output. Then Trisha Paytas joined as co-host in September 2020 and the graph becomes a different document. Monthly views tripled within weeks. The peak months of the Frenemies Era outperformed the entire preceding three years of the podcast, and the show did it in nine months.
When Frenemies ended in June 2021 — abruptly, on-camera, mid-episode — views dropped back toward baseline within a single month. Leftovers launched that September and added a new audience, generating a secondary bump visible in the 2022 data. But it never approached Frenemies numbers. After Leftovers ended in October 2023, the chart enters its current phase: a slow, grinding decline with no structural catalyst in sight. The mountain is the story. Everything else is the aftermath.
Even at its post-2023 lows, the H3 Podcast pulls millions of monthly views. The brand did not collapse — it contracted to its core. The audience that remains watches longer episodes with more commitment than the casual Frenemies-era viewer. The cliff looks dramatic because Frenemies was genuinely anomalous. The current numbers are not a failure; they are what a major podcast looks like without a viral co-host dynamic driving weekly drama.
era_lines <- data.frame(
date = as.Date(c("2020-09-15","2021-06-08","2021-09-26","2023-10-07")),
label = c("Frenemies\nPremiere","Frenemies\nFinale",
"Leftovers\nPremiere","Leftovers\nFinale"),
color = c(art_highlight, art_highlight, art_secondary, art_secondary),
vjust = c(1.3, 4.5, 1.3, 1.3)
)
p1 <- h3 |>
filter(channel == "H3 Podcast") |>
mutate(month_floor = floor_date(date, "month")) |>
group_by(month_floor) |>
summarise(monthly_views = sum(view_count, na.rm = TRUE)) |>
ggplot(aes(x = month_floor, y = monthly_views)) +
geom_area(fill = art_secondary, alpha = 0.15) +
geom_line(color = art_secondary, linewidth = 0.8) +
geom_vline(data = era_lines,
aes(xintercept = date, color = color),
linetype = "dashed", linewidth = 0.6) +
geom_text(data = era_lines,
aes(x = date, y = Inf, label = label,
color = color, vjust = vjust),
hjust = -0.08, size = 2.7, fontface = "bold") +
scale_color_identity() +
scale_y_continuous(labels = label_number(scale = 1e-6, suffix = "M")) +
scale_x_date(date_breaks = "1 year", date_labels = "%Y") +
labs(
title = "THE FRENEMIES ERA IS A MOUNTAIN ON THE GRAPH",
subtitle = "Monthly Total Views, H3 Podcast Channel, 2017-2026",
x = NULL, y = "Monthly Views",
caption = "Data: YouTube Data API v3 | Artometrics Original Dataset\n- ARTOMETRICS"
) +
theme_artometrics()
ggsave("chart1_era_timeline.png", plot = p1,
path = "charts", width = 12, height = 7, dpi = 300, bg = "white")
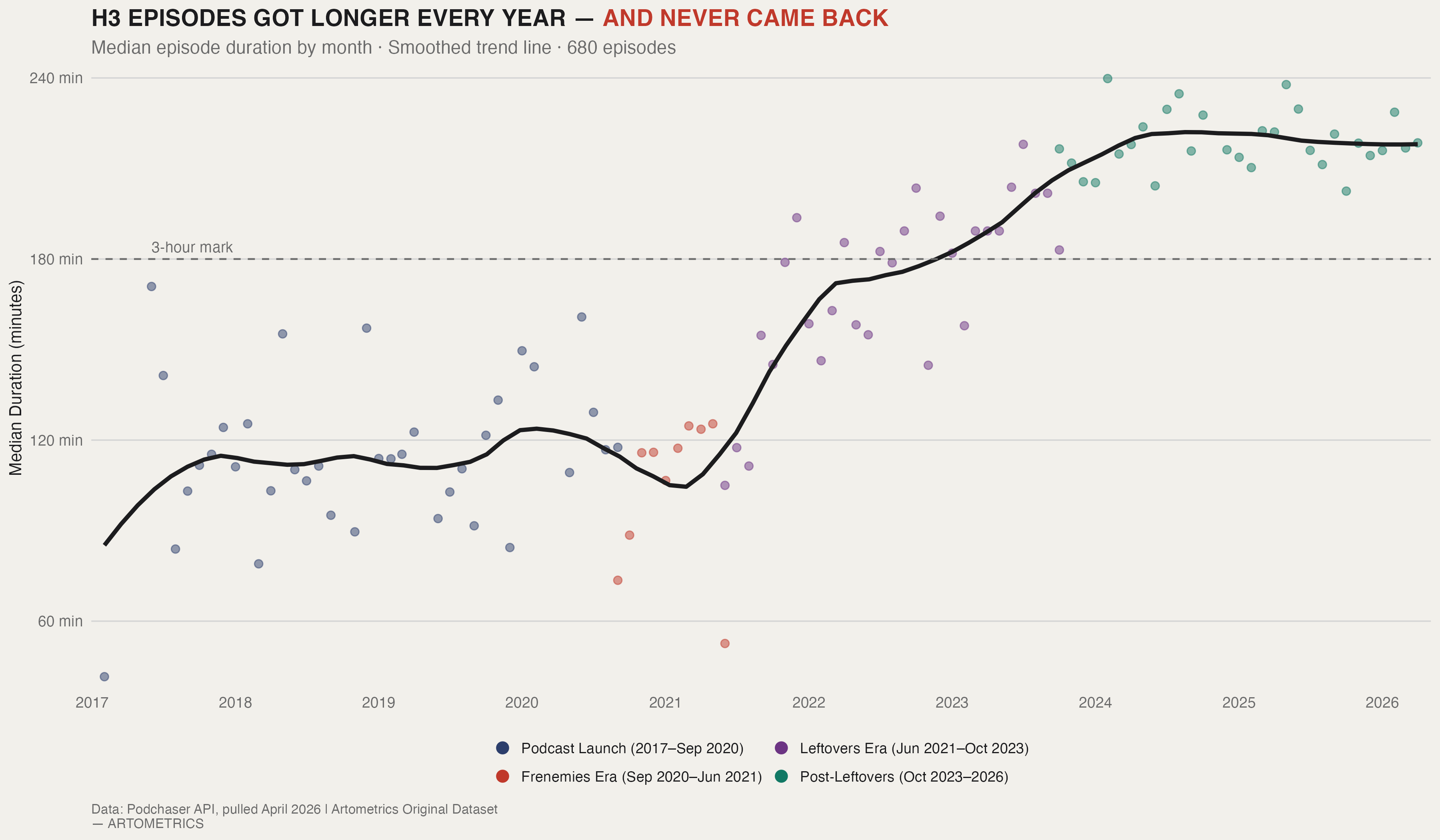
When H3 launched the podcast in 2017, the median episode ran 42 minutes. That's a commute. By 2024, the median had crossed 220 minutes — longer than most feature films. The chart shows this wasn't a sudden format change; it was a slow, continuous drift upward that compounded year over year until a new normal was established. No single episode caused it. No announcement reset it. The show just kept going longer, and the audience kept watching.
The clearest structural break in the duration data isn't a spike — it's a floor shift. Before 2022, monthly medians regularly dipped below 120 minutes. After 2022, they never did. The show locked into 3-hour-plus territory and stayed there. Leftovers (2021) normalized the extended format; by the time it ended (2023), the audience had been conditioned to expect marathon sessions as the default. That conditioning didn't reverse when Leftovers ended.
In 2024, H3 published far fewer episodes than in prior years — but duration hit its all-time high, with months regularly clearing 220–240 minutes. The show was publishing less but asking more from the audience that stayed. Each episode became a larger commitment, not a smaller one. The fans who remained weren't casual — they were in for 4 hours at a time.
p2_data <- episodes |>
mutate(
airDate = as.Date(airDate),
month = floor_date(airDate, "month"),
era = case_when(
airDate < as.Date("2020-09-15") ~ "Podcast Launch (2017-Sep 2020)",
airDate < as.Date("2021-06-08") ~ "Frenemies Era (Sep 2020-Jun 2021)",
airDate < as.Date("2023-10-07") ~ "Leftovers Era (Jun 2021-Oct 2023)",
TRUE ~ "Post-Leftovers (Oct 2023-2026)"
),
era = factor(era, levels = era_levels_dur)
) |>
group_by(month, era) |>
summarise(median_min = median(length_min, na.rm = TRUE), .groups = "drop")
p2 <- ggplot(p2_data, aes(x = month, y = median_min)) +
geom_point(aes(color = era), size = 2, alpha = 0.5) +
geom_smooth(method = "loess", span = 0.25, se = FALSE,
color = art_dark, linewidth = 1.2) +
geom_hline(yintercept = 180, linetype = "dashed",
color = art_mid, linewidth = 0.5) +
annotate("text", x = as.Date("2017-06-01"), y = 184,
label = "3-hour mark", color = art_mid, size = 3.2, hjust = 0) +
scale_color_manual(values = era_colors_dur,
guide = guide_legend(nrow = 2, override.aes = list(size = 3, alpha = 1))) +
scale_x_date(date_breaks = "1 year", date_labels = "%Y") +
scale_y_continuous(breaks = seq(0, 300, by = 60),
labels = function(x) paste0(x, " min")) +
labs(
title = "H3 EPISODES GOT LONGER EVERY YEAR — AND NEVER CAME BACK",
subtitle = "Median episode duration by month · Smoothed trend line · 680 episodes",
x = NULL, y = "Median Duration (minutes)", color = NULL,
caption = "Data: Podchaser API, pulled April 2026 | Artometrics Original Dataset\n- ARTOMETRICS"
) +
theme_artometrics()
ggsave("chart2_duration_drift.png", plot = p2,
path = "charts", width = 12, height = 7, dpi = 300, bg = "white")
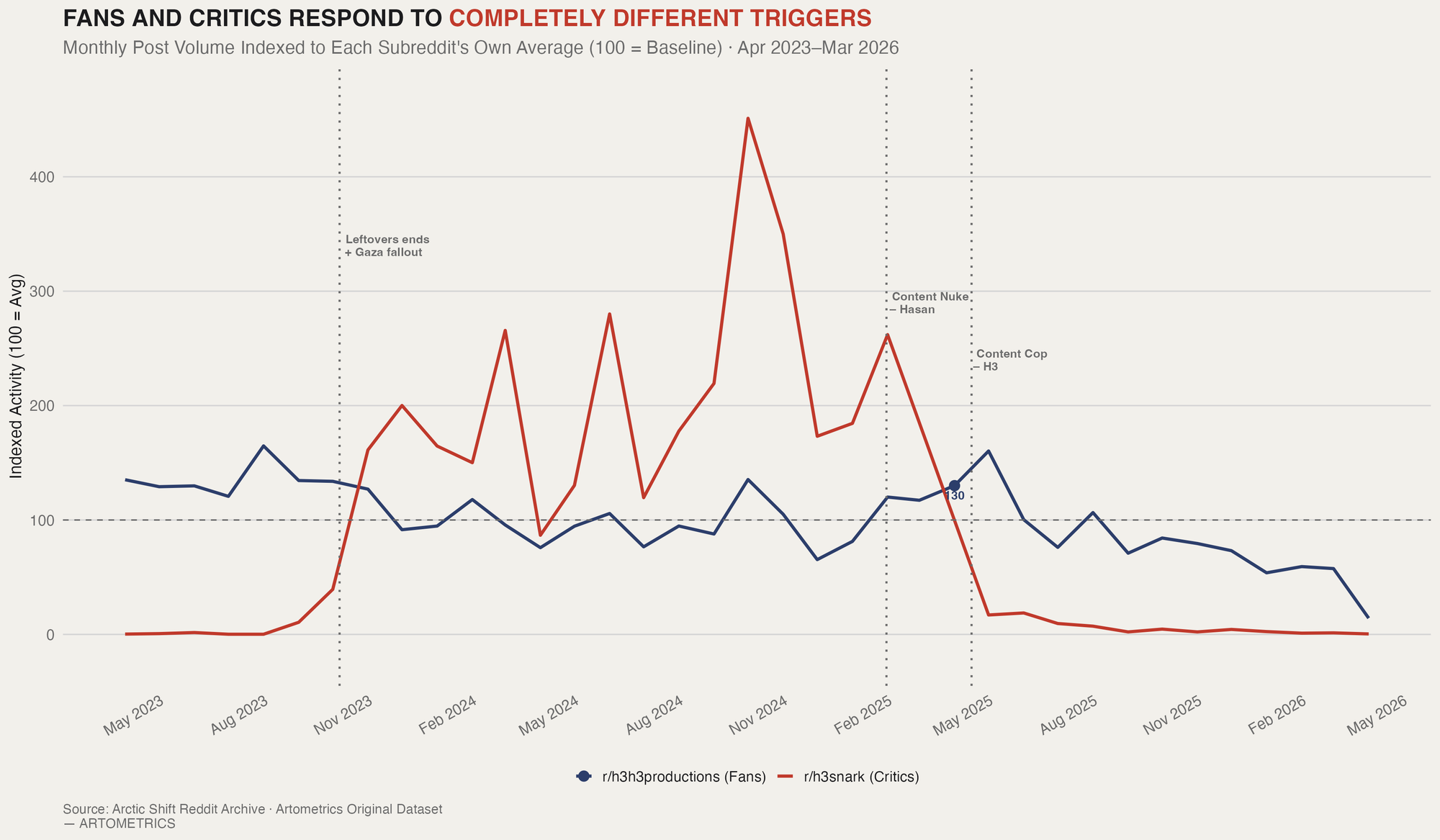
The indexed chart removes the raw scale difference between subreddits and asks a cleaner question: when did each community spike relative to its own normal? The answer is almost never at the same time. When the iDubbbz Content Cop dropped on April 16, 2025 — the first Content Cop in years, explicitly targeting the H3 brand — r/h3snark hit its all-time peak at more than 3.5× its own average. The fan sub barely registered the same event. The two communities were watching completely different shows.
The cliff in the snark data after May 2025 isn't a controversy dying down — it's a subreddit going dark. After Klein issued copyright claims against r/h3snark moderators and threatened legal action, the sub announced an indefinite hiatus. The index collapsed to near zero within weeks. The fan sub continued its slow decline — below its own average but still functional. The snark community didn't fade. It was shut down. That distinction matters: one line represents organic audience erosion, the other represents a legal intervention.
The blue line tells its own quieter story. The fan sub never spikes the way snark does — no single event moves it dramatically above baseline. But the trend is unmistakably downward. Fewer new things to discuss, fewer viral moments to dissect, fewer reasons to post. The legal drama — the Content Cop, the streamer lawsuits — barely registered. Whatever drives fan engagement on r/h3h3productions, it isn't courtroom news.
window_start <- as.Date("2023-04-01")
fan_monthly <- reddit |>
filter(month >= window_start) |>
count(month) |>
mutate(source = "r/h3h3productions (Fans)")
snark_monthly <- snark |>
filter(month >= window_start) |>
count(month) |>
mutate(source = "r/h3snark (Critics)")
combined <- bind_rows(fan_monthly, snark_monthly) |>
group_by(source) |>
mutate(index = (n / mean(n, na.rm = TRUE)) * 100) |>
ungroup()
vlines <- data.frame(
date = as.Date(c("2023-10-07","2025-01-31","2025-04-16")),
label = c("Leftovers ends\n+ Gaza fallout",
"Content Nuke\n- Hasan",
"Content Cop\n- H3"),
y = c(340, 290, 240)
)
p3 <- ggplot(combined, aes(x = month, y = index, color = source)) +
geom_line(linewidth = 0.9) +
geom_hline(yintercept = 100, linetype = "dashed",
color = art_mid, linewidth = 0.4) +
geom_vline(data = vlines, aes(xintercept = date),
color = art_mid, linetype = "dotted",
linewidth = 0.6, inherit.aes = FALSE) +
geom_text(data = vlines,
aes(x = date, y = y, label = label),
color = art_mid, size = 2.5, fontface = "bold",
hjust = -0.07, lineheight = 0.9, inherit.aes = FALSE) +
scale_color_manual(values = c(
"r/h3h3productions (Fans)" = art_secondary,
"r/h3snark (Critics)" = art_highlight
)) +
scale_x_date(date_breaks = "3 months", date_labels = "%b %Y") +
labs(
title = "FANS AND CRITICS RESPOND TO COMPLETELY DIFFERENT TRIGGERS",
subtitle = "Monthly Post Volume Indexed to Each Subreddit's Own Average (100 = Baseline)",
x = NULL, y = "Indexed Activity (100 = Avg)", color = NULL,
caption = "Source: Arctic Shift Reddit Archive · Artometrics Original Dataset\n- ARTOMETRICS"
) +
theme_artometrics() +
theme(legend.position = "bottom",
panel.grid.major.x = element_blank(),
axis.text.x = element_text(angle = 30, hjust = 1))
ggsave("chart3_reddit_activity.png", plot = p3,
path = "charts", width = 12, height = 7, dpi = 300, bg = "white")
The YouTube data captures view counts as of the April 2026 pull — not at time of publication. Older videos have had years to accumulate views through algorithmic recommendations and search, which means early h3h3Productions videos are systematically over-represented in lifetime view totals relative to their original performance. The era-based analysis on the H3 Podcast channel is less affected because the comparison is within-channel across time.
The Arctic Shift Reddit archive is comprehensive but not guaranteed complete. Deleted posts and accounts banned before archival are absent. The r/h3snark data begins in April 2023 — the sub's founding — so pre-2023 critical community activity is unrepresented. Any conclusions about the fan-vs-critic dynamic are bounded by that window.
Episode duration data from Podchaser is self-reported and may include inconsistencies for older episodes, live streams published as podcast episodes, and bonus or clip content. Episodes with missing duration values were excluded from Chart 2. Chart 3 indexes each subreddit to its own average across the Apr 2023–Mar 2026 window — a subreddit with low early activity will show inflated index values in later high-activity periods, which may slightly affect r/h3snark peak readings.
The H3 data tells a story about what happens when a creator brand builds its peak moment around someone else. The Frenemies Era was genuinely anomalous — nine months of co-host-driven drama that tripled the podcast's monthly viewership and created a ceiling the show has never approached since. The chart is unambiguous about this. The current audience is not a collapse; it is a correction back to what the brand can sustain on its own terms.
The duration data adds a different dimension. The show that emerged from the Frenemies aftermath is structurally different from the one that preceded it — longer, less frequent, more demanding. Whether that format is a creative choice or a symptom of a contracting audience is a question the data cannot answer. Both explanations fit the numbers.
The Reddit chart is the most structurally interesting of the three. It documents not just audience behavior but audience management: a creator using legal tools to suppress a critic community. The snark subreddit's cliff is not organic. It is the result of a deliberate intervention. The fan sub's slower decline runs in parallel and suggests the underlying engagement problem would exist regardless. Two different communities, two different trajectories, one brand caught between them.
YouTube Data API v3. Google. https://developers.google.com/youtube/v3
Artometrics Original Dataset (April 2026). H3 Podcast YouTube Network, 2013–2026. Compiled via YouTube Data API v3. https://github.com/Artometrics/h3
Podchaser. (2026). H3 Podcast episode data, 2017–2026. Retrieved via Podchaser API v1. https://api.podchaser.com
Arctic Shift Reddit Archive. (2026). r/h3h3productions and r/h3snark post data. Retrieved April 2026. https://arctic-shift.photon-reddit.com
Google Trends. (2026). Search interest data: h3h3, ethan klein, frenemies, teddy fresh. Retrieved via gtrendsR v1.5.2. https://trends.google.com
This report was researched, written, designed, and produced in active collaboration with Claude AI (Anthropic). The data pipeline, statistical analysis, chart design, written analysis, narrative structure, and visual styling were all developed through a directed partnership between human editorial judgment and AI execution. The research questions, editorial instincts, interpretive framing, and brand vision are ours. The execution was a collaboration. We document this not as a disclaimer but as a description of how we actually work, and as a position: we believe this is what serious data journalism looks like when the tools available are used honestly and at full capacity.
— Artometrics Editorial